

Die Automobilindustrie steht derzeit vor großen Veränderungen. Bis 2030 ist zu erwarten, dass der Großteil der Fahrzeuge elektrifiziert sein wird. Dabei wird gerade die Konnektivität eine zunehmend wichtige Rolle spielen und damit verbundene Technologien wie Digitaler Städtevorantreiben. Konnektivität wird sich zu einem integralen Bestandteil des autonomen Fahrens entwickeln – im Bestreben, die Sicherheit aller Teilnehmer im Straßenverkehr ständig zu verbessern. Einem Wandel werde auch die zukünftigen Geschäftsmodelle unterworfen sein. Während Fahrzeuge bislang zumeist als Eigentum erworben werden (zumindest im privaten Consumer Markt), verlagert sich das Kaufverhalten absehbar eher in Richtung Shared Services. Das autonome Fahren selbst sorgt für viel Bewegung, denn im Wesentlichen findet unter den Herstellern derzeit ein Wettlauf um die erste Markteinführung eines autonomen Fahrzeugs statt und viele High-Tech-Unternehmen und Start-ups streben selbst die Entwicklung autonomer Fahrzeuge an. Etablierte Autobauer deren Fokus und Stärke bisher auf der Entwicklung der physikalischen Fahrzeugplatform war, reagieren auf diese Entwicklung mit dem Kauf technologieorientierter Start-ups, der Bildung von Konsortien mit anderen Herstellern und marktführenden Unternehmen sowie hohen Investitionen in Forschung und Entwicklung, damit sie in der Lage sind, den bevorstehenden Wandel zu meistern.
Wettbewerbs- und Marktdruck ist allerdings nicht immer der einzig entscheidende Grund, warum Unternehmen Kooperationen und Zusammenschlüsse immer stärker propagieren. Die Entwicklung autonomer Fahrzeuge ist außerordentlich komplex und daher extrem zeit- und kostenintensiv.
Das Ziel der gesamten Entwicklung ist das vollautonome Fahren zu ermöglichen. Das heißt, alle Entscheidungen, die in heutigen Fahrzeugen von menschlichen Fahrzeuglenkern getroffen werden, werden langfristig durch elektronische Systeme getätigt. Diese Entscheidungen basieren einzig und allein auf den Informationen, die aus den Sensoren (Radar, Lidar, GPS, Ultraschall, Fahrzeug Daten) permanent und in Echtzeit geliefert werden sowie auf Erfahrungen aus vielen früheren Tests (Modelle). Mangelhafte Entwicklung und Implementierung dieser Systeme kann gravierende Folgen haben, die bis zum Verlust von Menschenleben führen können. Dies zu vermeiden hat die oberste Priorität. Abgesehen von jeglichen ethnischen Aspekten würde dies auch einen verheerenden finanziellen sowie Image- Schaden für die jeweilige Herstellermarke darstellen. Um ein autonomes Fahrzeug auf den Markt zu bringen, muss daher jedes denkbare Szenario antizipiert und so angelegt werden, dass Fehler und damit Unfälle nach bestem Wissen und Gewissen vermieden werden. Angesichts des exponentiellen Wachstums der möglichen Szenarien auf dem Weg zur vollständigen Autonomie ist es nicht wirklich möglich, noch zu unseren Lebzeiten jedes denkbare Szenario zu testen. Getestet wird also so viel, wie im Rahmen des Möglichen liegt. Doch was ist in einem Umfeld potenzieller sich daraus erwachsender Rechtsstreitigkeiten sinnvoll und im Rahmen des Möglichen? Tatsächlich ist die Entwicklung vollständig autonomer Fahrzeuge unglaublich komplex und birgt zahlreiche Risiken. Daher sollte es keine Überraschung sein, dass die etablierten Automobilhersteller und Marktführer bei ihren Tests überaus konservativ vorgehen. Ähnlich wie im Bereich des Halbleiterchip-Designs geht es hier beim Testen um Genauigkeit und die Abdeckung vieler verschiedener Szenarien. Um ein Auto auf den Markt zu bringen, müssen die Testdaten, mit denen es zugelassen wird, sowohl gründlich als auch realistisch sein. Obwohl die Möglichkeiten zur Simulation verschiedener Szenarien heutzutage umfassend sind, müssen praktisch alle Unternehmen letztendlich reale Sensordaten verwenden, die auf realen Straßen aufgezeichnet wurden, um ihre Tests durchzuführen. Die Realität kann in der Praxis nicht genauer dargestellt werden als mit realen Daten. Video, LiDAR, Radar, Sonar – die Daten aller Sensoren, die für den autonomen Betrieb des Fahrzeugs erforderlich sind, werden von Testfahrzeugen aufgezeichnet, um sie später in einem Labor wiederzugegeben und die finale Hardware gegen diese Daten zu testen. Dabei geht es nicht nur darum, Unfälle zu vermeiden, sondern auch darum die smarteste Lösung zu validieren. Nicht zuletzt auch deshalb, um allen rechtlichen Anforderungen Genüge zu tun.
Die Society of Automotive Engineers (SAE) hat sechs Autonomie-Stufen definiert, beginnend bei Stufe 0, wobei eigentlich nur Fahrzeuge der Stufen 4 oder 5 als wirklich autonom gelten. Stufe 4 ist nur für Fahrzeuge mit autonomer Technologie in bestimmten Bereichen vorgesehen – z. B. im Stadtzentrum – während Stufe 5 für autonome Fahrzeuge in allen Bereichen gilt; das Lenkrad wird hier nicht benötigt. Mit dem Übergang von weniger komplexen, niedrigeren Stufen zur vollständigen Autonomie steigt auch der Umfang der erfassten Sensordaten. Ein wichtiger Aspekt, den es auch zu berücksichtigen gilt, ist die Haftung. Bis einschließlich Stufe 3 ist der menschliche Fahrer immer für das verantwortlich, was durch und mit dem Fahrzeug im realen Straßenverkehr passiert. Nur mit den Stufen 4 und 5 sehen wir einen Haftungsübergang vom menschlichen Fahrer auf den Hersteller. Ein Großteil der aktuellen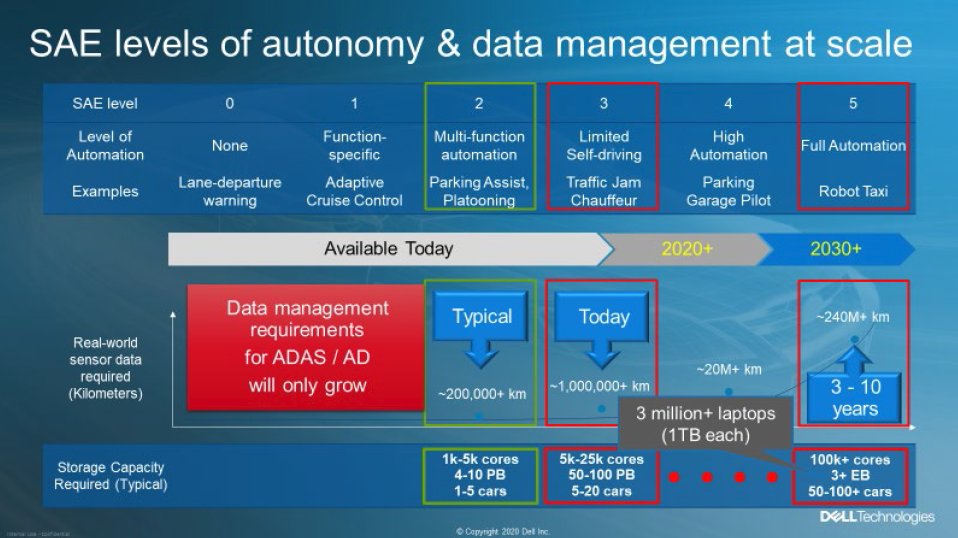 Fahrzeuge, die sich täglich auf unseren Straßen bewegen sind mit Funktionen der SAE Stufe 2 ausgestattet. Nur wenige Unternehmen treten derzeit in Märkte mit Funktionen der Stufe 3 ein – von denen einige deaktiviert wurden, während die Hersteller darauf warten, dass die Haftungsgesetze mit der Technologie Schritt halten. Dennoch konzentrieren sich viele Entwicklungen auf Funktionen der Stufe 3. Um ein solches Fahrzeug auf den Markt zu bringen, sind in der Regel Zehntausende von CPU-Cores und 50 bis 100 Petabyte Speicherplatz für die aufgezeichneten Sensordaten erforderlich – das sind eine Menge Daten – und es werden kontinuierlich mehr. Um die Auswirkungen der Datenmengen umfassend begreifen zu können, sollten wir einen genaueren Blick auf den Lebenszyklus der Sensordaten eines typischen ADAS/AD-Projekts werfen.
Fahrzeuge, die sich täglich auf unseren Straßen bewegen sind mit Funktionen der SAE Stufe 2 ausgestattet. Nur wenige Unternehmen treten derzeit in Märkte mit Funktionen der Stufe 3 ein – von denen einige deaktiviert wurden, während die Hersteller darauf warten, dass die Haftungsgesetze mit der Technologie Schritt halten. Dennoch konzentrieren sich viele Entwicklungen auf Funktionen der Stufe 3. Um ein solches Fahrzeug auf den Markt zu bringen, sind in der Regel Zehntausende von CPU-Cores und 50 bis 100 Petabyte Speicherplatz für die aufgezeichneten Sensordaten erforderlich – das sind eine Menge Daten – und es werden kontinuierlich mehr. Um die Auswirkungen der Datenmengen umfassend begreifen zu können, sollten wir einen genaueren Blick auf den Lebenszyklus der Sensordaten eines typischen ADAS/AD-Projekts werfen.
Nachdem der Umfang des Projekts definiert wurde ist in der Regel der erste Schritt das Erfassen der gewünschten Daten durch die in den Testfahrzeugen integrierten Sensoren. Je nach Projektumfang werden dazu mehrere dieser Testfahrzeuge (teilweise bis zu 100 Fahrzeuge pro Projekt) nach vorher genau festgelegten Routen (diese können sich quer über den Globus erstrecken) auf die Straßen geschickt. Die Fahrzeuge, welche von ausgebildeten Testfahrern bewegt werden, zeichnen kontinuierlich die erzeugten Sensordaten im Fahrzeug auf besonders schnellen und robusten Speichersystemen auf. Zum Übertragen dieser im Fahrzeug gesammelten Daten (oft 30 – 60 TB per Fahrerzyklus) in ein zentrales Rechenzentrum, werden die Speichermedien oft mehrfach täglich aus dem Fahrzeug entfernt und entweder direkt lokal mit entsprechender Verbindungsbandbreite oder zeitnah im Rechenzentrum in sogenannte „Ingest Stations“ eingelegt. Hier werden die Daten hoch performant direkt auf die zentralen Speichersysteme dem sogenannten „Data Lake“ übertragen und den nachfolgenden Prozessen zu Verfügung gestellt. Als Nächstes müssen die Sensordaten „angereichert“ werden. Das bedeutet, dass jemand – oder etwas – Boundingboxen um Fahrzeuge, Fußgänger, Hindernisse, Fahrbahnmarkierungen, Straßenschilder usw. zeichnen muss, also im Grunde alles, was das Fahrzeug in seiner unmittelbaren Umgebung identifizieren können muss.
Schließlich werden verschiedene Simulationsmodi angewendet oder es beginnt die Software-in-the-Loop-Simulation (SiL). An dieser Stelle kommt ein globales Modell zum Einsatz, mit dem eine Umgebung geschaffen wird, in der das Steuergerät (ECU – Electronic Control Unit) getestet werden kann. Dies erfolgt ebenfalls in einer Simulation. Tatsächlich gibt es zwei Arten von Simulationen: die Open-Loop- und die Closed-Loop-Simulation. Die Open-Loop-Simulation bedient sich der erfassten Sensordaten, die in ein simuliertes Steuergerät eingespielt werden. Bei einer Closed-LoopSimulation werden die Sensordaten selbst synthetisch und im laufenden Prozess erzeugt. Der Vorteil der Closed-LoopVariante besteht darin, dass der Simulator tatsächlich in Echtzeit auf das Verhalten des Steuergeräts reagieren kann. Der Simulator erzeugt zum Beispiel synthetische Sensordaten, die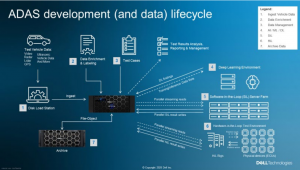 dem Steuergerät mitteilen, dass sich vor dem Auto ein Hindernis befindet. Als Reaktion darauf lenkt das Steuergerät das Auto um das Hindernis herum. Der Simulator reagiert dann, indem er Sensordaten erzeugt, die auf das Manöver reagieren, womit sich der Loop schließt. Daher spricht man hier von einem „Closed Loop“. Obwohl die erfassten Sensordaten eine genauere Darstellung ermöglichen, sind sie weniger flexibel. Was sie erfassen, ist das, was aufgezeichnet wird. Mit synthetischen Sensordaten lässt sich genau das gewünschte Szenario simulieren. Um also ein Szenario zu testen, in dem etwa ein Känguru am Time Square bei Nacht und bei starkem Schneefall eine asphaltierte Straße überquert, muss man nur den Simulator entsprechend programmieren und schon geht es los. Dabei können Zehntausende von SiL-Tests – als Opensowie als Closed-Loop-Simulationen – parallel allein für die SAE-Stufe 3 durchgeführt werden. Schließlich kommen wir zu Hardware-in-the-Loop Tests (HiL). Dieses Verfahren ähnelt dem physikalischen Prototyping, bei dem ein tatsächliches Steuergerät in einer realen Live-Umgebung getestet wird. Dies erfolgt möglicherweise mit Aktoren für Lenkung und Bremsvorgänge sowie andere physikalische Komponenten – entsprechend dem jeweiligen Fahrerassistenzsystem und den spezifischen Tests, die durchgeführt werden. Aus Sicherheits- und Kostengründen geschieht dies immer noch in einem Labor, statt mit einem echten Auto auf einer echten Strecke (einem Testgelände) zu fahren. Die Sensordaten werden über einen „HiL-Prüfstand“ in die Hardware eingespeist, der die Sensordaten in die präzisen elektrischen Signale umwandelt, die das physikalische Steuergerät erwarten würde, wenn es in einem realen Fahrzeug installiert wäre. Wie beim SiL-Test können die Sensordaten für HiL-Tests im Closed Loop von einem Simulator im laufenden Prozess erzeugt oder für HiL-Tests im Open Loop vom Datenspeicher übertragen werden. HiL-Simulationen sind kostenintensiver als SiL-Simulationen und laufen langsamer. Da es sich um echte Hardware handelt, muss sie mit realen Geschwindigkeiten laufen. Ein 60-Sekunden-Video erfordert 60 Sekunden zum Testen. In einer reinen Simulationsumgebung kann es tausendmal schneller abgespielt werden – abhängig von der Leistung des Simulators und den zugrunde liegenden Serverkernen und Grafikprozessoren. Entsprechend macht es Sinn so viele HiL-Prüfstände wie möglich zu bauen, da sie verglichen mit der Simulation langsamer laufen. In der Regel werden mehr als 100 HiLPrüfstände parallel betrieben. Sobald das Fahrzeug schließlich in Produktion geht, müssen abschließend alle aufgezeichneten Sensordaten und die gesamte Simulationsumgebung archiviert werden. Das mag trivial klingen, aber die Daten müssen im Falle eines späteren Problems schnell verfügbar sein. Softwarefehler werden häufig erst später entdeckt, was zu einem Rückruf führen kann – insbesondere, wenn es dabei um die Sicherheit geht. Die Hersteller fordern, dass die Testumgebung innerhalb von Tagen bis Wochen wieder einsatzbereit ist – je nach Service-Level-Agreement (SLA), lokalen Gesetzen und dem Risikoniveau, das der Hersteller zu akzeptieren bereit ist. Die schnelle Datenrückgewinnung wirkt sich zusätzlich auf die Speicherkosten aus, da sie gängige Archivierungstechnologien wie kostengünstige Tapes rein technisch ausschließen könnten. Die Daten müssen zudem über die gesamte Lebensdauer des Fahrzeugs aufbewahrt werden. Die individuellen Regularien sind aktuell noch nicht auf die ADAS/AD-Technologie abgestimmt, so dass die „Lebensdauer von Fahrzeugen“ sehr unterschiedlich definiert wird. Konservative Unternehmen bewahren diese Daten bis zu 50 Jahre lang auf. In der Regel sind 30 Jahre ausreichend.
dem Steuergerät mitteilen, dass sich vor dem Auto ein Hindernis befindet. Als Reaktion darauf lenkt das Steuergerät das Auto um das Hindernis herum. Der Simulator reagiert dann, indem er Sensordaten erzeugt, die auf das Manöver reagieren, womit sich der Loop schließt. Daher spricht man hier von einem „Closed Loop“. Obwohl die erfassten Sensordaten eine genauere Darstellung ermöglichen, sind sie weniger flexibel. Was sie erfassen, ist das, was aufgezeichnet wird. Mit synthetischen Sensordaten lässt sich genau das gewünschte Szenario simulieren. Um also ein Szenario zu testen, in dem etwa ein Känguru am Time Square bei Nacht und bei starkem Schneefall eine asphaltierte Straße überquert, muss man nur den Simulator entsprechend programmieren und schon geht es los. Dabei können Zehntausende von SiL-Tests – als Opensowie als Closed-Loop-Simulationen – parallel allein für die SAE-Stufe 3 durchgeführt werden. Schließlich kommen wir zu Hardware-in-the-Loop Tests (HiL). Dieses Verfahren ähnelt dem physikalischen Prototyping, bei dem ein tatsächliches Steuergerät in einer realen Live-Umgebung getestet wird. Dies erfolgt möglicherweise mit Aktoren für Lenkung und Bremsvorgänge sowie andere physikalische Komponenten – entsprechend dem jeweiligen Fahrerassistenzsystem und den spezifischen Tests, die durchgeführt werden. Aus Sicherheits- und Kostengründen geschieht dies immer noch in einem Labor, statt mit einem echten Auto auf einer echten Strecke (einem Testgelände) zu fahren. Die Sensordaten werden über einen „HiL-Prüfstand“ in die Hardware eingespeist, der die Sensordaten in die präzisen elektrischen Signale umwandelt, die das physikalische Steuergerät erwarten würde, wenn es in einem realen Fahrzeug installiert wäre. Wie beim SiL-Test können die Sensordaten für HiL-Tests im Closed Loop von einem Simulator im laufenden Prozess erzeugt oder für HiL-Tests im Open Loop vom Datenspeicher übertragen werden. HiL-Simulationen sind kostenintensiver als SiL-Simulationen und laufen langsamer. Da es sich um echte Hardware handelt, muss sie mit realen Geschwindigkeiten laufen. Ein 60-Sekunden-Video erfordert 60 Sekunden zum Testen. In einer reinen Simulationsumgebung kann es tausendmal schneller abgespielt werden – abhängig von der Leistung des Simulators und den zugrunde liegenden Serverkernen und Grafikprozessoren. Entsprechend macht es Sinn so viele HiL-Prüfstände wie möglich zu bauen, da sie verglichen mit der Simulation langsamer laufen. In der Regel werden mehr als 100 HiLPrüfstände parallel betrieben. Sobald das Fahrzeug schließlich in Produktion geht, müssen abschließend alle aufgezeichneten Sensordaten und die gesamte Simulationsumgebung archiviert werden. Das mag trivial klingen, aber die Daten müssen im Falle eines späteren Problems schnell verfügbar sein. Softwarefehler werden häufig erst später entdeckt, was zu einem Rückruf führen kann – insbesondere, wenn es dabei um die Sicherheit geht. Die Hersteller fordern, dass die Testumgebung innerhalb von Tagen bis Wochen wieder einsatzbereit ist – je nach Service-Level-Agreement (SLA), lokalen Gesetzen und dem Risikoniveau, das der Hersteller zu akzeptieren bereit ist. Die schnelle Datenrückgewinnung wirkt sich zusätzlich auf die Speicherkosten aus, da sie gängige Archivierungstechnologien wie kostengünstige Tapes rein technisch ausschließen könnten. Die Daten müssen zudem über die gesamte Lebensdauer des Fahrzeugs aufbewahrt werden. Die individuellen Regularien sind aktuell noch nicht auf die ADAS/AD-Technologie abgestimmt, so dass die „Lebensdauer von Fahrzeugen“ sehr unterschiedlich definiert wird. Konservative Unternehmen bewahren diese Daten bis zu 50 Jahre lang auf. In der Regel sind 30 Jahre ausreichend.
In Anbetracht des Trends, ein vollständig autonomes Auto bauen zu wollen, müssen wir sorgfältig überlegen, wie wir mit all diesen Daten umgehen. Für SAE-Stufe 5 haben wir es mit mehreren Exabytes an zu erfassenden Daten zu tun. Ganz zu schweigen von den Hunderten von CPU-Cores und Tausenden von Grafikprozessoren, die für die Tests benötigt werden. Und natürlich müssen all diese Daten noch über Jahrzehnte gespeichert werden. Aus infrastruktureller Sicht ist es wichtig zu beachten, dass all die verschiedenen Entwicklungsstadien – einschließlich Datenaufnahme, Anreicherung, KI/ML/DL, SiL- und HiL-Tests – parallel ablaufen. Und da all diese Daten nicht am ersten Tag erfasst werden können (in der Regel dauert die Erfassung mindestens ein Jahr), muss der Speicher im richtigen Maßstab skaliert werden, um immer mehr Daten aufnehmen zu können – sowie immer mehr Tests zu unterstützen.
Wie wir sehen, ist die Entwicklung eines autonomen Fahrzeugs also ein Balanceakt. Daten sind das Herzstück jeglicher Entwicklungsprozesse und damit von besonders hohem Wert. Doch diese wertvollen Daten bringen auch Kosten für die passende Infrastruktur mit sich. Es dürfte also keine Überraschung sein, dass zahlreiche Automobilunternehmen die Cloud als Alternative für die Datenspeicherung – sowie für den sofortigen Zugriff auf Grafikprozessoren und CPU-Kerne – ohne Vorabinvestitionen in Betracht ziehen.
Für Ingenieure und Entwickler ist die Cloud die perfekte Lösung. Dank des starken Wettbewerbs gibt es eine breite Angebotspalette der Hersteller mit zahlreichen Tools für Analyse, KI und Datenmanagement. Und natürlich bieten alle Speicher- und Rechenleistung – einschließlich Grafikprozessoren – auf Abruf. Es steht außer Frage, dass die Cloud eine Menge bietet, und viele Unternehmen haben die Migration in die Cloud fest in ihre Geschäftsstrategie integriert. Grundsätzlich bietet eine Cloud viele Vorteile – einige davon gelten auch für die Entwicklung von Fahrerassistenzsystemen und autonomen Fahrzeugen. Die Public Cloud verspricht zudem eine kostengünstige Speichermöglichkeit, was angesichts der Notwendigkeit, Hunderte von Petabyte an Sensordaten zu speichern, besonders reizvoll ist. Flexibilität, unendliche Skalierbarkeit und Verbrauchsmodelle, die Agilität und Anpassungfördern – was könnte man sich mehr wünschen?
Unglücklicherweise ist die Cloud für alle da und Vorsicht ist geboten, wenn es darum geht, die lokale Infrastruktur durch eine Public Cloud zu erweitern oder sogar zu ersetzen. Auch wenn Cloud-Lösungen viel bieten bedeutet das nicht, dass sie für jede Art von Aufgabe perfekt geeignet sind. Eine „Cloud-first“-Geschäftsstrategie, also die bevorzugte Migration von Daten in die Cloud, ist häufig anzutreffen. Allerdings ist sie nicht für jede Branche die ideale Strategie – und die Automobilindustrie ist da keine Ausnahme.
Um die Einführung einer Public Cloud für die ADAS/AD-Entwicklung in Betracht zu ziehen, ist es am besten, sich an den bestehenden Daten zu orientieren. Im Rahmen einer „Data-first“-Strategie lässt sich der ADAS-Entwicklungszyklus noch einmal rekapitulieren und aufzeigen, wie es sich auswirken würde, wenn die Datenspeicherung und/oder ihre Verarbeitung in der Public Cloud stattfinden würden.
Der erste Schritt ist nach wie vor die Datenerfassung. Die Daten werden nach wie vor von Fahrzeugflotten erfasst und müssen schließlich aufgenommen und in die Cloud hochgeladen werden. Die Gesamtmenge der Daten, um die es dabei geht, kann sehr groß sein – zum Beispiel zu groß, um WAN-Verbindungen zu nutzen. Nicht selten werden Ingest-Stationen benötigt, die sich physisch in der Nähe des Speichers befinden müssen. Dies kann jedoch ein unmittelbares Problem für die Public Cloud darstellen: Was ist, wenn diese Hardware in ihrem Rechenzentrum nicht zugelassen ist?
Eine weitere Herausforderung ist die Sicherheit. Wir alle wissen, dass Public Clouds heutzutage weitgehend sicher sind. ADAS/AD-Sensordaten erfordern aber ein erhöhtes Sicherheitsniveau. Es gibt Bedenken hinsichtlich des Datenschutzes (z. B. müssen Gesichter und Nummernschilder unscharf sein) und staatliche Sicherheitsvorschriften, denen zufolge bestimmter Länder den Datenverkehr aus ihrem Land beschränken. Einige Länder gehen so weit, den direkten Zugang nur auf von der Regierung genehmigte Einrichtungen zu beschränken. Wenn eine Public Cloud genutzt wird, muss also sichergestellt sein, dass sie alle lokalen Einschränkungen berücksichtigt – und den Technikern dennoch den Zugriff auf diese Daten von überall auf der Welt ermöglicht.
Clouds sind heute primär für objektbasierte Datenspeicherung optimiert. Die Entwicklung autonomer Fahrzeuge hängt jedoch entscheidend von der dateibasierten Speicherung ab. In der Public Cloud gibt es Einschränkungen in Bezug auf den Umfang, die Verfügbarkeit im richtigen Maßstab und die Speicherleistung. Gerade für diese Art von Aufgaben ist Leistung entscheidend – vor allem in Bezug auf KI. Abgesehen davon, dass es sich bei der Public Cloud um einen weniger optimalen Speicher handelt, ist sie auch eine gemeinsam genutzte Ressource. Das bedeutet, dass die Speicherleistung sowohl unzureichend als auch unvorhersehbar sein kann. Dies kann sich wiederum in Projektverzögerungen und Kostenerhöhungen niederschlagen. Übrigens gilt dasselbe auch für die Verarbeitung. Es ist nicht ungewöhnlich, dass Nutzer bei großem Bedarf an CPU/GPU-Kernen abgewiesen werden oder Tage bis Wochen warten müssen. Mitunter ist die Cloud ein äußerst geschäftiger Ort, an dem sich viele Nutzer tummeln.
Cloud-Anbieter speichern gern Daten – sogar kostenlos. Der Haken: Sie geben sie nicht gerne wieder zurück. Austrittsgebühren können kostspielig sein, und sobald Daten bei einem bestimmten Cloud-Anbieter gespeichert sind, sind sie dort gebunden – unabhängig von den Kosten und der Qualität der angebotenen Tools. Die gute Nachricht ist, dass diese Daten sicher und immer verfügbar sind – solange man bereit ist dafür zu zahlen, wenn man sie jemals anderswohin streamen will.
Zurück zum HiL-Test. Zu diesem Workload gehört das Streaming von Daten in physische Hardware. Diese Hardware hat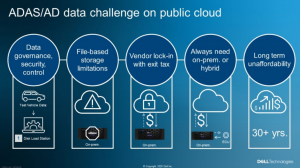 sehr präzise Zeitvorgaben und ist ein wesentlicher Teil dessen, was am HiL-Prüfstand durchgeführt wird. Da physische Hardware zu empfindlich auf Latenzzeiten reagiert, ist ein Vor-Ort-Speicher erforderlich. Das ist vergleichbar mit dem Streamen eines Films über das Internet. Wenn das Video einmal einfriert oder verpixelt aussieht, weil das Internet überlastet ist, macht man sich
sehr präzise Zeitvorgaben und ist ein wesentlicher Teil dessen, was am HiL-Prüfstand durchgeführt wird. Da physische Hardware zu empfindlich auf Latenzzeiten reagiert, ist ein Vor-Ort-Speicher erforderlich. Das ist vergleichbar mit dem Streamen eines Films über das Internet. Wenn das Video einmal einfriert oder verpixelt aussieht, weil das Internet überlastet ist, macht man sich
wahrscheinlich keine Sorgen. Das ist der Preis, den man für einen Video-Streaming-Dienst bezahlt. Für HiL-Tests ist dies aber nicht akzeptabel – denn es spiegelt nicht die Realität und ist nicht ausreichend
genau. HiL-Prüfstände müssen sich also physisch in der Nähe des Rechenzentrums befinden. Wie bei Ingest-Stationen ist anzunehmen, dass ein herkömmlicher Public-Cloud-Anbieter es nicht gestattet, einen HiLPrüfstand – komplett mit Aktoren für Lenkung, Bremsen und Beschleunigung – in seinem Rechenzentrum einzurichten. Es bleibt also keine Wahl als die Daten in den Vor-Ort-Speicher zu kopieren, bevor sie übertragen werden können. Durch das andauernde Streamen von Daten rund um die Uhr machen sich jedoch die Kosten erst richtig bemerkbar.
Sobald das Fahrzeug in Produktion ist, könnte man meinen, dass sich die Kosten allmählich verringern, doch dem ist nicht so. Denn alle diese Daten müssen noch archiviert werden. Das bedeutet fortlaufende Gebühren für die nächsten 30–50 Jahre, über die verhandelt werden muss. Vor allem, wenn der Cloud-Anbieter weiß, dass die Daten bei ihm gebunden sind. Auch Kosteneinsparungen durch günstige Archivierungslösungen kommen nicht in Frage, da die Daten möglicherweise für einen zukünftigen Rückruf von Fahrzeugen benötigt werden, vielleicht um die Hardware umzustellen, oder auch um einen Corner-Case-Fehler zu beheben. In jedem Fall handelt es sich um OEM-mandatierte SLAs, die eine Wiederherstellung der gesamten Validierungsumgebung innerhalb weniger Wochen oder Monate erfordern können. Angesichts der Datenmenge von mehreren Petabytes zeigt sich die Herausforderung, für die kostengünstige Speicherlösungen längst nicht mehr gut genug sind.
Die Verfolgung einer „Cloud-first“-Strategie kann also in einigen Branchen sinnvoll sein und vielleicht auch für einige Workloads innerhalb der Automobilindustrie. Aber für Aufgaben in Zusammenhang mit Fahrerassistenzsystemen hat die Übertragung von Daten an einen einzigen Cloud-Anbieter unbeabsichtigte Konsequenzen. Die wenigen Start-ups, die über die frühen Entwicklungsstadien hinaus überlebt haben, können das bestätigen.
Die gute Nachricht: Es ist noch nicht alles verloren. Die Public Cloud bietet durchaus auch Vorteile, von denen ADAS/ADEntwicklungsteams profitieren können. Und es gibt Alternativen zu einer reinen Public-Cloud-basierten Lösung, mit denen die Flexibilität maximiert und gleichzeitig die Kosten – und Risiken – minimiert werden können. Insbesondere in Bezug auf das autonome Fahren, bei dem die Daten im Mittelpunkt des gesamten Design-Flows stehen, wird deutlich, dass ein Data-first-Ansatz für die Cloud erforderlich ist. Das bedeutet, dass es sinnvoll ist die geschäftlichen und technischen Vorteile der Cloud zu nutzen, aber nur wenn es darum geht, den Wert der Daten und nicht die Nutzung der Cloud zu maximieren. Eine Migration muss also sowohl aus technischer als auch aus geschäftlicher Sicht sinnvoll sein.
Aus der reinen Geschäftsperspektive ist es wünschenswert, den Anbieter zu wählen, der – für alle benötigten Aufgabenbereiche – über die besten Tools seiner Klasse verfügt und den bestmöglichen Gesamtpreis bietet. Das sind die Anforderungen heute genauso wie in 30 Jahren. Aber wer würde aus unternehmerischer Risikoüberlegung alle Daten – die „Kronjuwelen“ jedes Unternehmens – an einen Konkurrenten weitergeben wollen? Vermutlich niemand, einige haben es jedoch getan.
Betrachtet man die Cloud aus einer technischen Perspektive, so wird Folgendes für die ADAS-Entwicklung benötigt:
• Die Kapazität, Tausende von Fällen gleichzeitig zu übertragen – die Aufgaben sind komplex und die Rechen- und Speicherleistung entsprechend hoch.
• Planbare Kosten – idealerweise mit unbegrenzter Bandbreite und ohne Eintritts- und Austrittsgebühren
• Planbare Leistung – ADAS/AD beruht auf dateibasierter Speicherung, nicht auf Objektspeicherung.
• Optimierte Arbeitsabläufe für Maschinelles Lernen sowie Deep Learning – dies erfordert Werkzeuge und die entsprechende Infrastruktur, um maximale Leistung zu erzielen. Zu beachten ist, dass die für KI/ML/DL verwendeten Grafikprozessoren in der Regel teuer sind – und datenhungrig. Sie erfordern die Speicherung mit der höchsten Leistung und somit den höchsten Kosten. Die überwiegende Mehrheit der ADAS/AD-Daten wird jedoch für HiL- und SiL-Tests verwendet, die keine so kostspielige Speicherung benötigen. Es gibt aber auch Überschneidungen. Der Cloud-Anbieter sollte in der Lage sein, die optimale Lösung für eine solch komplexe Umgebung zu bieten.
• Analytik und Datenmanagement – ADAS-Daten müssen durchsuchbar sein; häufig setzt man auch Analyseverfahren ein, um interessante Szenarien zu ermitteln und die Qualität der Datensätze zu überprüfen. Ähnlich wie bei KI/ML/DL-Tools verfügt nicht jeder Public-Cloud-Anbieter über die idealen Tools dafür.
• Gemeinsame Nutzung von Daten – Hersteller tauschen häufig mit bevorzugten Lieferanten Daten und Dienstleistungen aus. Möglicherweise führt der Hersteller die abschließende Sensorfusion über mehrere ADASSubsysteme durch, die ihrerseits von mehreren Anbietern stammen. Dafür müssen sie die Möglichkeit haben, den Zugang zu mehreren Subunternehmern gemeinsam zu nutzen – und auch zu beschränken.
• Direkter Zugriff auf Server und Speicher – für die Datenübernahme sowie Hardware-in-the-Loop-Tests. Auch wenn der Wunsch besteht das gesamte Rechenzentrum in die Cloud zu verlagern gibt es keine Alternative zur Vor-Ort-Speicherung. Insbesondere bei der Arbeit mit physischer Prototyp-Hardware, die sich räumlich in der
Nähe dieser Rechen- und Speichergeräte befinden muss.
Die Lösung für all diese Herausforderungen ist die hybride Multi-Cloud. Mit der Dell Technologies Cloud für die Automobilbranche wird beispielsweise ein Service angeboten, der bei Bedarf vor Ort mit einer verwalteten privaten Cloud-Lösung kombiniert werden kann. Dabei sind die Daten über Direktverbindungen zu mehreren Cloud-Anbietern gleichzeitig verfügbar. Obwohl die Daten in der Dell Cloud verbleiben, können sie gleichzeitig in mehreren Public Clouds sowie in einer On-premise-Cloud gespeichert und bereitgestellt werden. Das Konzept ist hier, einen Mittelweg zu bieten, bei dem die hybride Cloud-Lösung einen Hochleistungszugriff auf die Public Cloud bietet – und zwar mit Latenzzeiten im einstelligen ms-Bereich –, so dass die Daten nicht mehr in die Public Cloud kopiert werden müssen. Der Zugriff erfolgt in Sekundenschnelle, wobei sich alle Vorteile der Cloud nutzen lassen, ohne Daten dorthin zu verschieben. Auch Daten aus der Hybrid-Multi-Cloud von Dell zu einem Public-Cloud-Anbieter zu kopieren ist einfach, denn der Zugang ist kostenlos.

Das Konzept einer hybriden Multi-Cloud bringt jedoch mehr als nur die Vermeidung von Austrittsgebühren. Es ermöglicht Nutzern, wirklich unabhängig von einem einzigen Cloud-Anbieter zu werden. Indem die Daten gleichzeitig mehreren Anbietern zur Verfügung stehen, lässt sich auswählen, welcher Anbieter zu einem bestimmten Zeitpunkt genutzt werden soll. Hinzu kommt die Option für dieselben Daten KI/ML/DL-Tools eines Anbieters zu nutzen und gleichzeitig große Datenanalyse-Tools eines anderen Anbieters einzusetzen.
Die Konkurrenz bei den Cloud-Anbietern ist groß. Dank dieses Wettbewerbs ist inzwischen eine unglaubliche Vielfalt an Tools von verschiedenen Anbietern erhältlich. Aber nur mit einem hybriden Multi-Cloud-Ansatz lassen sich tatsächlich die besten Tools mehrerer Anbieter kombinieren. Somit können die Tools für maschinelles Lernen des einen Anbieters mit dem Abfrage-Tool eines anderen Anbieters sowie den bevorzugten Tools eines dritten Anbieters kombiniert werden – und das gleichzeitig und ohne jemals Daten kopieren zu müssen. Der Wettbewerb unter den Cloud Providern erlaubt Anwendern hier viel Auswahl und Flexibilität.
Das Herzstück von Dells Multi-Cloud-Storage für die Automobilindustrie ist Powerscale. PowerScale blickt auf eine langjährige Erfahrung im Bereich der Entwicklung autonomer Fahrzeugsysteme zurück. Wenn es darum geht Zehn- bis Hunderttausende von parallelen Streams zu managen, die simultan auf Speicherkapazitäten zugreifen und bei denen es auf die Skalierung der Speicherleistung ankommt, ist PowerScale die ideale Lösung. Anwender im Bereich der ADASEntwicklung sind in der Lage hoch performante KI-Anwendungen, Tausende von SiL- und Hunderte von HiL-Aufgaben mit geringer Latenzzeit und sogar Analysen gleichzeitig auszuführen, ohne jemals Daten replizieren zu müssen.
Für Anwender, die Daten bereits in einer Amazon-Cloud nutzen und nach einer Lösung für Hardware-in-the-Loop-Tests vor Ort suchen, arbeitet Dell Technologies mit AWS zusammen. Es wurde eine cloud-fähige HiL-Funktion bei der PowerScale vor Ort mit dem Datenmanagementsystem DataIQ genutzt wird, entwickelt. Daten werde von AWS für HiL-Tests vor Ort kopiert.
Weitere Informationen dazu unter.
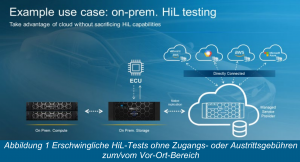
Dell Technologies kooperiert mit Microsoft Azure, um mit ExpressRoute Local eine Verbindung mit hoher Bandbreite (bis zu 100 Gbps) und niedriger Latenz (bis zu 1,2 ms) zur Cloud bereitzustellen. Diese Lösung ermöglicht die optimale Kombination von Speicherung und Verarbeitung in der Cloud für datenintensive Workloads mit hohem E/A-Durchsatz. Mit dieser Lösung können Workloads, die viele temporäre Schreibzugriffe auf den Speicher erfordern, kosteneffizient und zuverlässig von den Anwendungsservices von Azure und der skalierbaren Storage-Performance von Dell Technologies profitieren.
Egal, ob man als Hersteller, Zulieferer oder Start-up die Vorteile der Cloud nutzen möchte, wichtig ist sich vorab umfassend zu informieren, bevor Daten und damit die Zukunft des Unternehmens einem einzigen Cloud-Anbieter anvertraut werden. Mit hybriden Multi-Cloud-Lösungen lassen sich eine Vielzahl von Optionen nutzen, um die Cloud dort einzusetzen, wo es wirtschaftlich sinnvoll ist und auch technologische Vorteile bringt.






